Introduction
There are a number of different computing facilities available at the University of York. Have you found any of the following when doing research on your own computer?
Your workload is taking a long time to run (>6hrs)
It uses all your machine's resources (compute cores or memory)
You need lots of memory
You need GPUs
You are either using or producing a lot of data
- You think you could cut your job into smaller chunks and process them at the same time
- You know you want to analyse larger datasets in the future.
We have a few different machines to use when you have these problems: individual large machines known as the research and teaching servers, and the Viking compute cluster, a connected group of hundreds of machines. Here will will give you a very brief introduction on how to access these machines.
The research and teaching servers
These servers are also known as the Linux Managed Service or LMS for short. There are currently four research servers (research0, research1, research2 and research3) and two teaching servers (teaching0 and teaching1). Detailed information on the server specifications can be found here. These machines are Desktops, similar to what you may have at home or in your office, but with a large number of compute cores and memory. This means that work that your local machine is struggling with may easily be run on one of these machines. You can log on to these machines from anywhere on campus, or off campus if you use the Virtual Private Network (VPN) or SSH gateway service. Some caveats:
- They are a shared machine which means a number of users may be logged on at the same time
- They run Linux so you need a little bit of Linux command line knowledge to get started
- If you are an undergraduate you will only have access to the teaching servers
- They get rebooted on the first Tuesday of every month, so any jobs running then will be killed
Exercise 1 - Logging into the research or teaching servers.
There are different ways to login to the LMS depending on what operating system you are running. We will break down the different options here.
Before You Login
If you have not changed your IT Services password since August 2013 then you must do so before you will be able to login. All user password changes are manage via the My IT Account web page. Click on the Password Management (IDM) link in the Manage Your Password field to change your password. You may be given the option to 'synchronise' your password; please use this option if you do not want to change your password. The password change (or synchronisation) may take a few minutes before it is visible to the servers.
Accessing research and teaching servers off campus
To access the research and teaching servers off campus you can either use the Virtual Private Network - VPN or the SSH gateway service (registration required). The instructions below should work if you log on through the VPN; the SSH service works slightly differently.
Access from a Windows desktop
Command-line access using PuTTY
PuTTY is available on all IT Services Managed Windows systems. It is pre-installed on Classroom PCs; on Office PCs you can install it from Run Advertised Programs / Software Center. It appears under "Internet Tools" on the start menu.
On unmanaged PCs you can download the installer from the PuTTY Website.
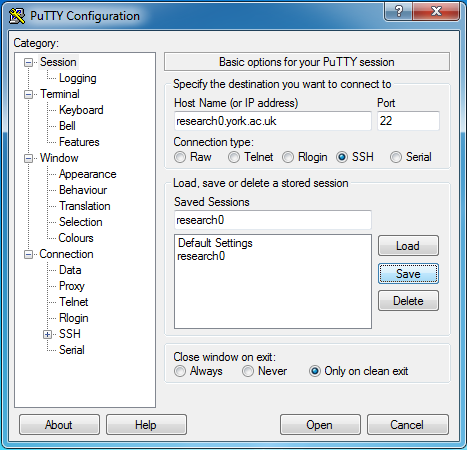
When you run PuTTY for the first time, enter the following settings to log on to the research0 server (or replace research0 with teaching0, research1 etc):
- Add the name "research0.york.ac.uk" to the 'Host Name' field
- Check the 'Connection Type' to SSH
- Type the name "research0" in 'Saved Sessions'
- Click 'Save'
- Expand the 'SSH' tab from the 'Connection' list in the 'Category' box
- Choose 'X11' from 'SSH' list
- Check 'Enable X11 Forwarding'
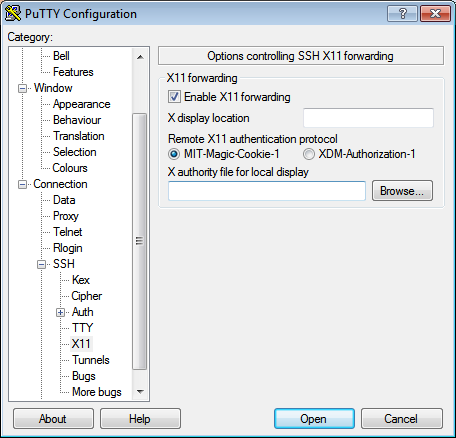
- Choose 'Session' from the 'Category' box
- Click 'Save'
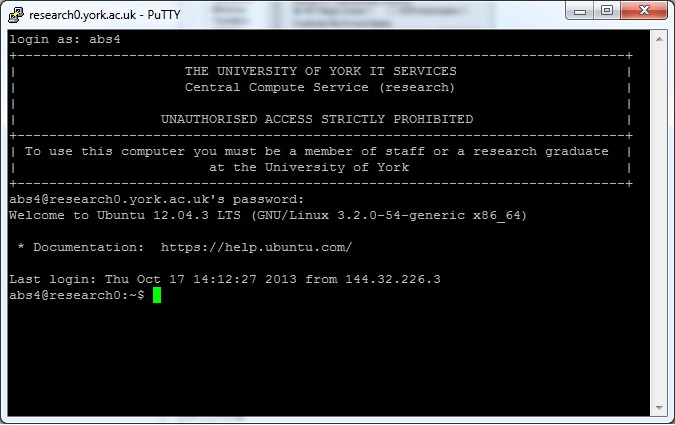
Connecting to research0
- Start PuTTY
- Select 'research0' from the 'Saved Sessions'
- Click 'Open'
- The first time you connect you will get a security alert showing the fingerprint of the server, labeled as 'ssh-rsa' or 'ssh-ed25519'. Check the fingerprint below for the label shown and click "Yes" to proceed if it matches.
ssh-rsa 2048 5c:43:e5:e6:57:e0:4d:9f:f8:b5:ca:52:2f:30:39:ef research0 ssh-rsa 2048 bb:1f:6e:58:fa:d7:23:0d:ae:b2:b2:e8:62:a0:e7:5c research1 ssh-rsa 2048 13:42:77:57:ad:33:67:12:a4:8f:d3:26:24:37:2c:e0 research2 ssh-rsa 2048 99:da:16:61:09:e0:19:1f:53:0e:2b:e9:2a:22:50:99 research3 ssh-rsa 2048 ac:7e:1e:2a:05:d8:a1:3b:cf:b5:77:48:d0:bb:8a:22 teaching0 ssh-rsa 2048 bb:de:33:ff:07:23:6b:0a:73:ad:1f:8a:57:b2:c7:77 teaching1 ssh-ed25519 5a:c9:c1:76:16:00:42:45:f9:e5:bd:63:5d:87:db:8a research0 ssh-ed25519 f4:51:59:b7:b5:74:1c:14:a7:2c:78:1c:11:1f:72:cc research1 ssh-ed25519 76:93:b3:2d:e0:73:cb:25:a5:9e:c7:bd:ce:76:8f:a2 research2 ssh-ed25519 64:b2:f0:11:93:fc:d7:ea:12:bb:90:bc:7d:06:75:cc research3 ssh-ed25519 f4:ff:10:59:1e:5f:21:10:14:59:6e:04:16:63:7d:95 teaching0 ssh-ed25519 bc:73:f8:4f:40:7a:6b:41:73:90:f6:77:2b:4f:aa:d5 teaching1
Graphical login using x2go
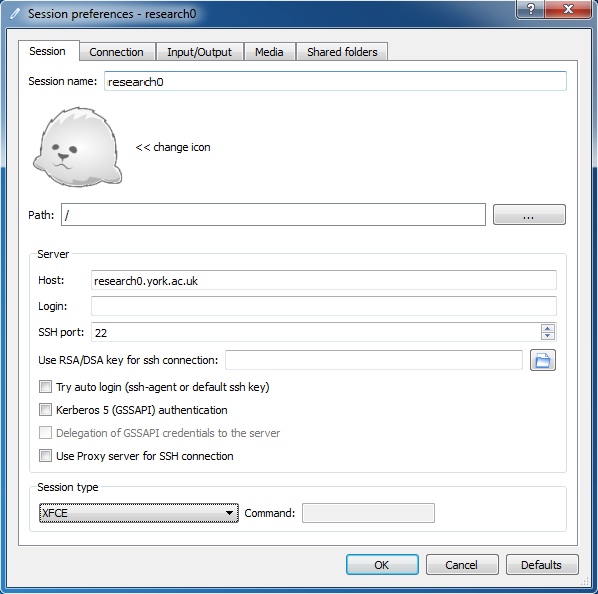
On unmanaged PCs you can download the installer from the x2go Website. You will need to configure the settings as follows for research0 (or replace research0 with the name of the server you want to use):
- If the "New session" panel does not appear, select the menu item "Session | New session..."
- Enter "research0" in the 'Session name' field at the top
- Enter "research0.york.ac.uk" to the 'Server: Host:' field
- Change the 'Session Type' to XFCE
- Click "OK" (all other settings can stay on default).
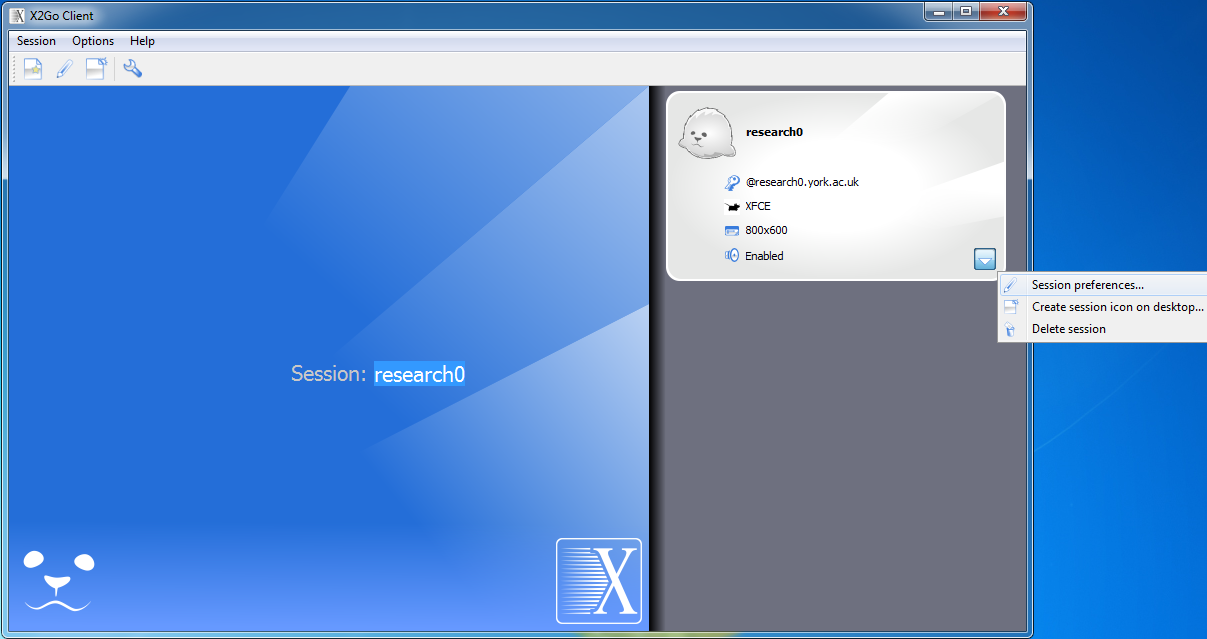
If you wish to change any settings:
- Cancel any login dialogs
- Click the pull-down on the corner of the panel and select "Session preferences..."
Access from a Mac
Go to the Finder on your Mac, find Applications, open the Utilities folder in Applications and then start the Terminal app from the Utilities folder. (You may wish to add Terminal to your Dock.) Then type the following, using your university username (abc123) instead ofusername. You don't need to type the $; this is an example of a prompt, which tells us the terminal is ready for us to type something. You should see something similar when you open Terminal, though it may be a bit longer (it may show your username for example). Just type anything from after the $.
$ ssh username@research0.york.ac.uk
For a graphical login, install and configure the x2go client software as described in the unmanaged Windows section above.
teaching0 and the other servers can be accessed in the same manner.
Access from a UNIX server or desktop
To login from a terminal window, type the following from your local machine with your university username (abc123):
$ ssh username@research0.york.ac.uk
If you require X forwarding, type:
$ ssh -X username@research0.york.ac.uk
You will be prompted for your IT Services password.
Accessing teaching0 is done in the same manner.
Using the research/teaching servers with the Linux command line interface
Once you have successfully logged into the research or teaching servers, they may look very different to what you are used to, particularly if you are used to using Windows. Please do not let this put you off. The research computing team have successfully managed to help many people use these computers who have never used the Linux command line before. It takes a bit of getting used to but the more you use it the easier and quicker it will become over time.
The command line, or shell, has been the major interface for the Unix/Linux operating system since it was first conceived in the late 1960s. The shell allows interaction with the operating system through a text based interface, rather than the graphical interface you are used to. While the graphical interface is easy to learn, and usually makes simple things easy to do, it can be hard to do complex things like operate on large numbers of files, or make different tools work together. The shell can be hard to learn, but is much more powerful and flexible than most graphical interfaces, so can be very useful for research, where we often want to try new things on large data sets.
In this tutorial, we will only scratch the surface of the shell's features, just to get you started, but we will note some further features at the end of the tutorial that you may want to look into.
The user starts the shell by logging into the computer with a userid and password:
****************************************************************************** *** THE UNIVERSITY OF YORK IT SERVICES *** *** *** *** THIS IS A PRIVATE COMPUTER *** *** UNAUTHORISED ACCESS STRICTLY PROHIBITED *** ****************************************************************************** login: user001 password: Last login: Mon Sep 8 14:12:44 2014 from gallifrey.york.ac.uk -bash-4.1$
The last line is a command prompt and it is the means by which the computer is telling you that it is ready to accept a command from you. If you do not see the prompt, the computer is probability still executing the last command you have typed. The user types commands which take the form:
program [ options ] [ arguments ]
Roughly speaking, program is the name of the program we want to run, arguments are objects we want to process (typically data files or folders), and options modify how the program will run. Options to a command are usually proceeded by a '-' or '- -' to differentiate them from arguments. The following exercise demonstrates using the echo program with a series of arguments and the ls program with or without options.
Exercise 2 - Running commands in the Linux shell
Displaying and editing the contents of files
There are a variety of different tools to help you display and edit the contents of your files. We will provide some examples below but you may find other ones which you prefer to use in the future.
Exercise 3 - Displaying the contents of files
Copying files and directories remotely
You may need to copy files from your machine at home to one of the research/teaching servers. There are a number of ways to do this.
Exercise 4 - Copying files from your machine to the research machines
There are different exercises on copying files dependent on what operating system you use on your local machine.
Copying Files To/From a Windows Desktop
WinSCP is an open source free SFTP client, SCP client, FTPS client and FTP client for Windows. Its main function is file transfer between a local and a remote computer. WinSCP is available on IT Services supported desktops or can be downloaded from http://winscp.net/eng/index.php.
Run WinSCP from the Start menu or double clicking on the icon on the desktop;
![]()
A login window will appear. Fill in the hostname and your username:
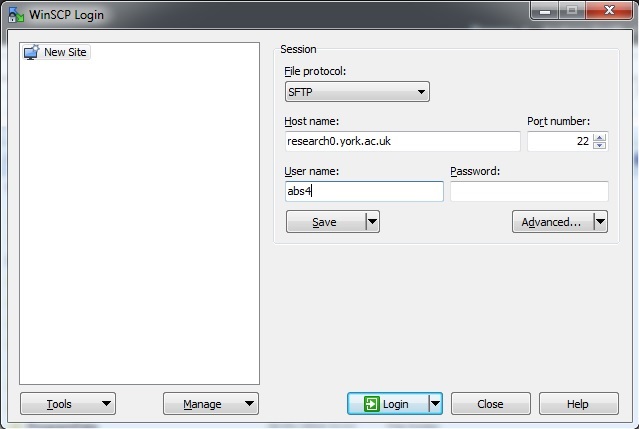
Running WinSCP
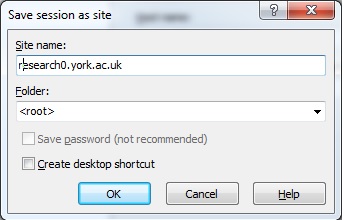
You can click the "Save" button to save the session details for future use:
Return to the login window and click the "Login" button. Some hosts may present you with an information window:
You will then be prompted for your password:
The file manager window will be displayed:
The drag-and-drop interface is a similar to Windows file manager and its use should be intuitive.
Finding and running programs on the research/teaching machines
There are many programs available on the research/teaching machines. Some programs can be used all the time (like ls, scp and rsync). Some programs need to be loaded using the module system. In this next section we will try both options and show you the best way to find the program you need for your teaching or research. If you find the software you need is not installed, please email itsupport@york.ac.uk and we will aim to install the software for you.
Exercise 5 - Running applications on the research/teaching machines.
Extra Information
This has been a very basic introduction to the command line, just to get you started. You may also want to look up the following features:
- Using pipes (|) to pass the output of one tool as input to the next, allowing you to make new tools by combining existing ones
- Redirecting input and output to files with >
- Using wildcard characters such as * to refer to many files or directories at once
- Writing scripts: saving a series of commands to a text file and then running the file as a program
- Running jobs in the background with &, nohup and nice
- Variables and options for environment customisation
- Command-line editing
- Command history (quick access to previous commands)
If you wish to learn more about how to use Linux command line there are a number of online resources. We do recommend The Unix Shell - Software Carpentry, where all the exercises and answers are available online. We also have our Online training resources page which provides various options depending on where you wish to get started.
What shall I do if I need more computational power?
The Viking Cluster
If you are finding that your code is still taking a long time to finish or you wish to scale your work, the Viking cluster may be what you need.
Viking is a large Linux compute cluster aimed at users who require a platform for development and the execution of small or large compute jobs.
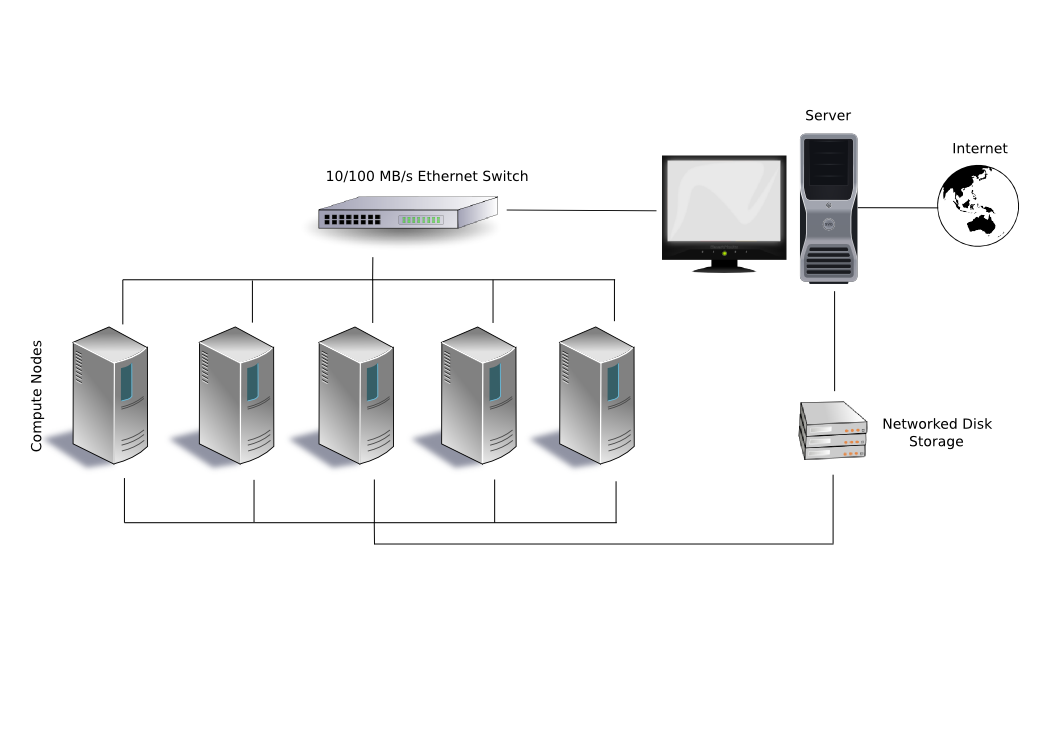
What is a cluster?
A cluster consists of many (hundreds or thousands) rack mounted computers called nodes. It would be similar to having hundreds of desktop computers sitting in the same room and able to talk to each other. Clusters are often accessed via login nodes, which can send jobs to the other nodes in the cluster. Your commands will not be run immediately, but will be sent to a queue, and run when there is space on the cluster to run them.
The Viking cluster is Linux based and can be accessed in a similar manner to the research servers, but instead of accessing, say, research0.york.ac.uk, you would access viking.york.ac.uk. We have extensive wiki pages on how to get started on Viking. Please see /wiki/spaces/RCS/pages/39159378 for further details and if you ever need help email itsupport@york.ac.uk where one the research computing team can assist you.
Viking is a multidisciplinary facility, supporting a broad spectrum of research needs, free at the point of use to all University of York researchers. Viking is as much a facility for learning and exploring possibilities as it is a facility for running well-established high-performance computing workloads. In this light, we encourage users from all Faculties, backgrounds and levels of ability to consider Viking when thinking about how computing might support their research.
To access Viking you need a user account, and your user account needs to be associated with a project code. Project codes are typically given to research groups; ask your PI for their code, and if they don't have one, ask them to fill in the Project Application Form. Once you have a project code, you can apply for a user account by filling in the User Application Form. It can take 24 hrs for new accounts to be processed. The Viking Wiki has more help on How to access Viking.